
Trados Language Cloud - Przygotowanie do pracy w przeglądarce
Jacek Mikrut | 21.11.2023
Trados to nie tylko klasyczna aplikacja, którą instalujemy na naszym komputerze z Windows, ale również aplikacja przeglądarkowa (w chmurze), która działa na dowolnym komputerze i systemie operacyjnym (np. MacOS, Linux, Android i in.).
Czym jest projekt w chmurowym Tradosie
W chmurowym Trados Language Cloud zawsze pracujemy z projektami. Projekt jest kontenerem na dokumenty.
Czym jest pamięć tłumaczeń (Translation Memory – w skrócie TM)
Pamięci tłumaczeń to bazy, w których zapisywane są nasze tłumaczenia, by następnie nam podpowiadać w trakcie pracy. Jest to kluczowy zasób tłumaczeniowy, dlatego zawsze powinniśmy dodawać TM do projektu. I nawet jeśli korzystamy z tłumaczenia maszynowego, to każde poprawne jak i poprawione przez nas zdanie również powinniśmy dodać (np. skrótem Ctrl Enter) do naszej pamięci!
Gdzie Trados Language Cloud trzyma projekty, pamięci, itd.
Zarówno projekt, jak i pamięci tłumaczeń oraz inne zasoby są zawsze zapisywane w chmurze. Oczywiście mamy możliwość pobrania wszystkiego na nasz komputer w dowolnej chwili.
Zaczynamy pracę!
Jak się zalogować do Trados Language Cloud
Można bezpośrednio z Tradosa Studio.
Najpierw klikamy przycisk logowania do chmury w prawym górnym rogu.
 Przycisk logowania do chmury Language Cloud
Przycisk logowania do chmury Language CloudJeżeli trzeba logujemy się do chmury swoimi danymi do konta tradosowego.
Po zalogowaniu ujrzymy rodzaj chmury, którą posiadamy. Trzeba ją kliknąć i uruchomi się przeglądarka z logowaniem do chmury. W moim przypadku muszę kliknąć pozycję Trados Studio Professional Cloud Capabilities.
 Posiadany rodzaj chmury oznaczony jest niebieskim kolorem. Kliknięcie tej pozycji uruchomi przeglądarkę i logowanie do chmury.
Posiadany rodzaj chmury oznaczony jest niebieskim kolorem. Kliknięcie tej pozycji uruchomi przeglądarkę i logowanie do chmury.
Ale jak się zalogować, jeżeli nie mamy możliwości (lub nie chcemy) instalować Tradosa Studio?
Uruchamiamy naszą przeglądarkę internetową.
Wpisujemy adres https://languagecloud.sdl.com/lc/. Można kliknąć link od razu.
Logujemy się swoimi danymi do konta tradosowego. Jeżeli nie logowaliśmy się jeszcze, to instrukcja jest tutaj.
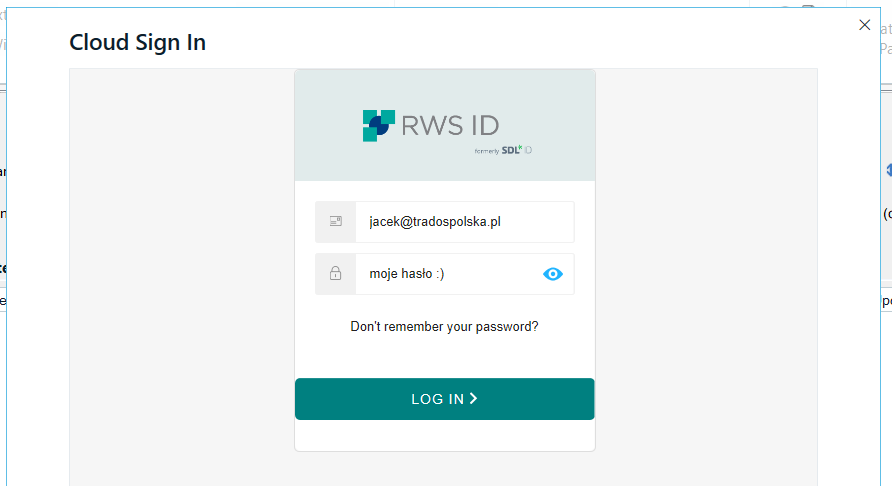
Jeżeli pojawi się okno z umową licencyjną i warunkami użytkowania, to żeby móc korzystać z aplikacji, musimy zaznaczyć pola oznaczone czerwoną gwiazdką i kliknąć Continue.

Po chwili pojawi się pulpit chmurowego Tradosa.



Przegląd interfejsu
Zanim przejdziemy dalej, warto pokrótce omówić, co znajdziemy na górnym pasku.

Dashboard – pulpit, na którym widać liczbę projektów, przetworzonych słów, zadań, itp.
Inbox – tradosowa skrzynka odbiorcza; w pracy indywidualnej raczej mało przydatna, przy pracy zespołowej to tutaj pojawiają się komunikaty o tym, co się dzieje w projektach.
Project – tu zakładamy projekty, przeglądamy projekty, statystyki i tłumaczymy.
Resources – tutaj zarządzamy pamięciami tłumaczeń, terminologią, silnikami tłumaczenia
maszynowego i innymi zasobami językowymi.
Customers – ta sekcja pozwala nam na organizowanie projektów i zasobów wokół klientów (nie trzeba z tego korzystać). Służy to dodatkowej organizacji i porządkowaniu pracy.
Terminology – dodatkowa zakładka do terminologii.
Przygotowanie zasobów
Chmurowy Trados wprowadza nową koncepcję – Translation Engine. Jest to kontener, do którego dodajemy pamięci tłumaczeń, terminologię i tłumaczenie maszynowe i dopiero taki Translation Engine dodajemy do projektu. Oczywiście możemy np. dodać do Translation Engine tylko pamięć tłumaczeń i w ten sposób pracować. Tylko taką pamięć najpierw trzeba utworzyć.
Tworzenie pamięci tłumaczeń (TM – Translation Memory)
Przechodzimy do Resources - Translation Memories i z listy wybieramy Translation Memories.
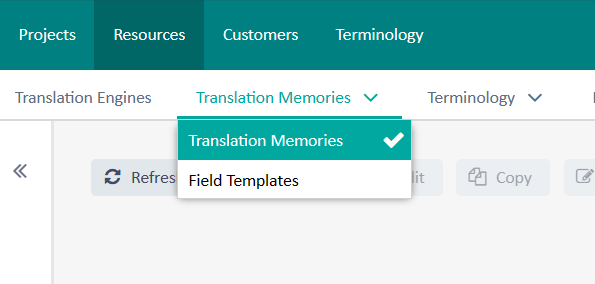
Klikamy przycisk + New Translation Memory.
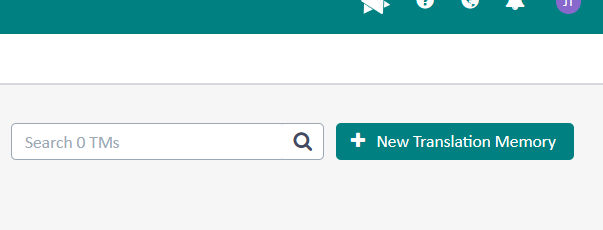
Pojawi się okno tworzenia pamięci tłumaczeń, w którym musimy wypełnić kilka pól.
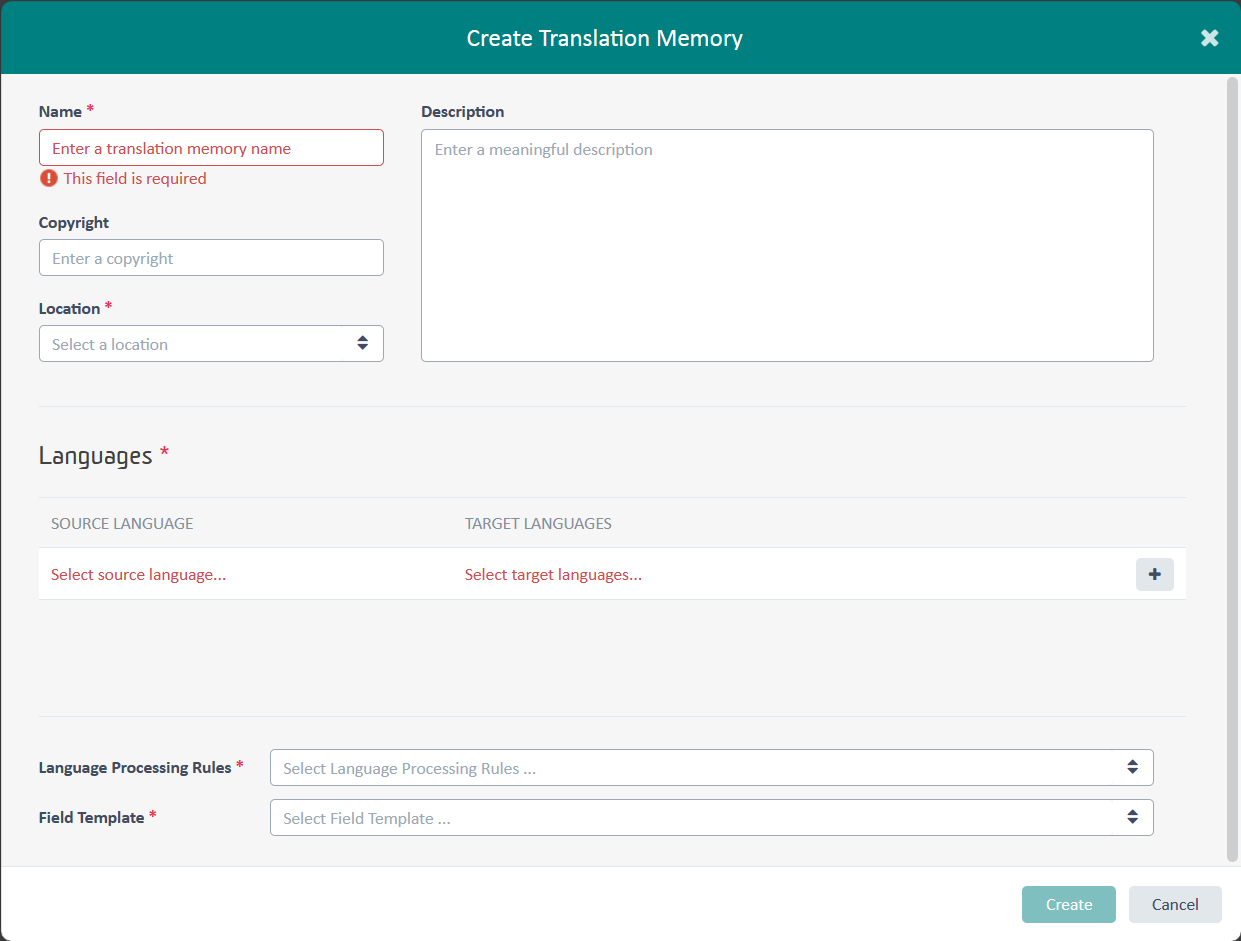
Poniżej widzimy, że pamięć tłumaczeń jest już praktycznie gotowa. Pozostało jeszcze kliknąć Create.
Name – nazwa pamięci tłumaczeń. Jeżeli tłumaczymy różne dziedziny (np. biologia, fizyka) i/lub tłumaczymy dla różnych klientów (np. Samsung, Huawei), dobrze jest tworzyć (i nazywać) pamięci dopasowane do dziedziny oraz klienta. Jak tłumaczymy tekst dla Samsunga, to wybieramy pamięć Samsunga, jeśli tłumaczymy chemię, to dobieramy pamięć z chemii. Dzięki temu nasze TM są spójne kontekstowo. Jedna TM do wszystkiego zazwyczaj nie jest dobrym pomysłem.
Na powyższym zrzucie ekranu tworzę pamięć dla klienta Wikipedia, który poza tym zleca mi kilka innych dziedzin, więc nazwę dziedziny też w nazwie pamięci. Na końcu dopisuję jeszcze parę językową z uwzględnieniem podgrupy. Inne przykłady nazw: Samsung smartfony enGB-pl, chemia enUS-pl, itp.
Description – dodatkowe informacje, które chcielibyśmy przechowywać razem z pamięcią. Na potrzebę tego samouczka wpisałem klienta oraz dziedzinę, ale normalnie to pewnie zostawiłbym to pole puste.
Location – miejsce zapisu pamięci w naszej chmurze. Jeżeli dodatkowo utworzyliśmy sobie klientów (Customers), to możemy daną pamięć przypisać do konkretnego klienta. Służy to organizacji i uporządkowaniu pracy. Ja nie utworzyłem żadnych klientów i wybrałem poziom Root jako miejsce na trzymanie swoich zasobów językowych.
Source Language / Target Language – określamy język źródłowy oraz docelowy.
Ważną kwestią przy wyborze języka źródłowego i docelowego jest podgrupa językowa. Trados pilnuje, żeby para językowa projektu zgadzała się z parą językową pamięci tłumaczeń (TM – Translation Memory). Dotyczy tovrównież podgrup językowych, dlatego English (United Kingdom) oraz English (United States) to dla Tradosa niekompatybilne języki. Jeżeli ustawimy nasz projekt w parze językowej np. English (United Kingdom) – German (Austria) to będziemy mogli użyć tylko pamięci o identycznej parze językowej oraz o identycznych podgrupach językowych!
Na co wpływa podgrupa językowa? Na dopasowanie słownika sprawdzania pisowni, rozpoznawanie formatu dat, walut, liczb, godzin, itd. i związaną z nimi automatyzacją. Jeżeli na początku trudno nam określić podgrupę, to w miarę możliwości najlepiej wybrać jakąś uniwersalną.
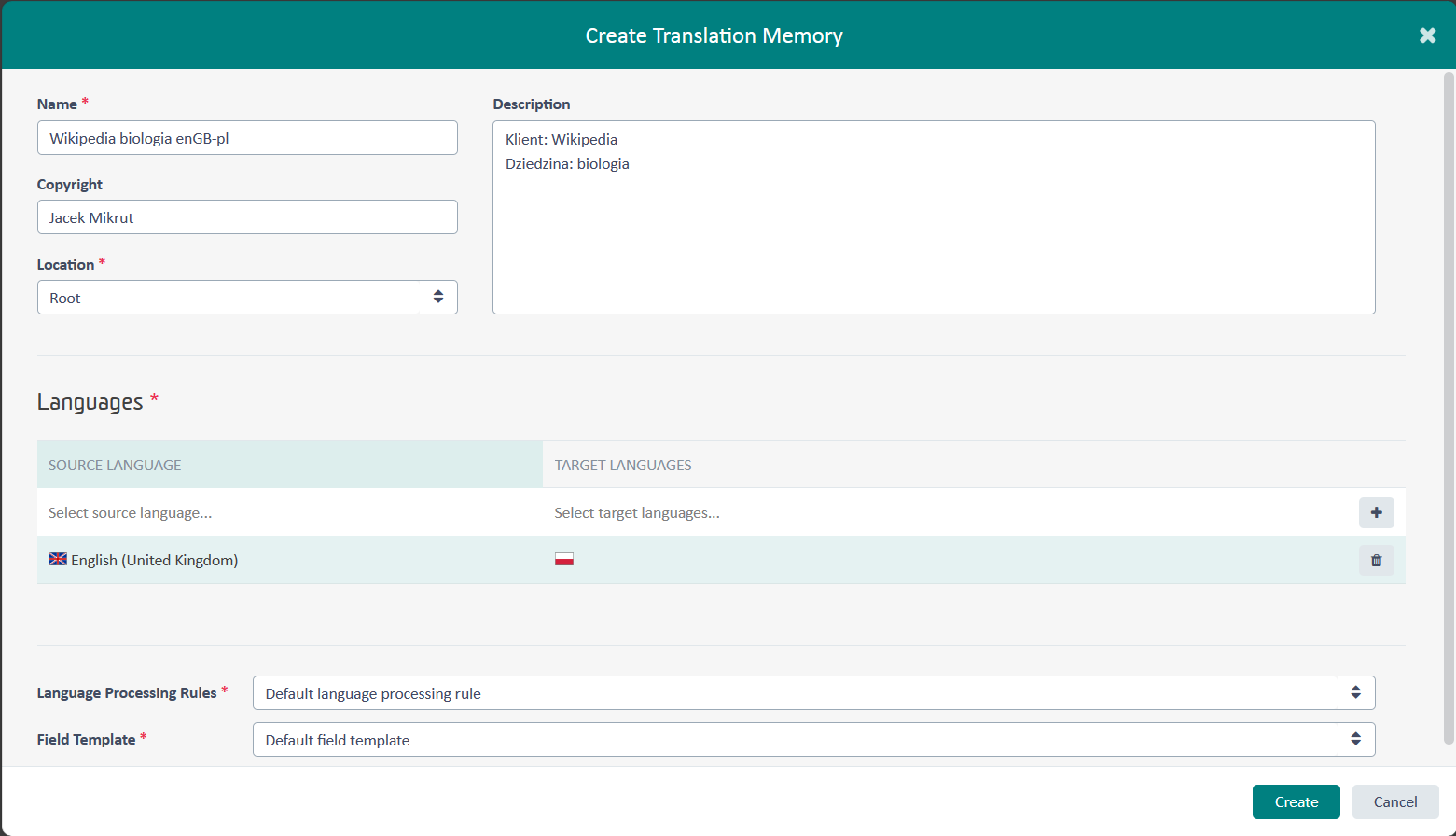
Language Processing Rules – ta pozycja powinna sama się wypełnić, kiedy wybierzemy Location. Jeżeli się nie wypełniła, należy kliknąć strzałki znajdujące się po prawej stronie i wybrać pozycję z listy.
Field Template – sytuacja identyczna jak z Language Processing Rules, czyli ta pozycja powinna sama się wypełnić, kiedy wybierzemy Location. Jeżeli się nie wypełniła, należy kliknąć strzałki znajdujące się po prawej stronie i wybrać dostępną pozycję z listy.
Teraz możemy już kliknąć Create, żeby powrócić do poprzedniego okna. Pojawi się informacja, że pamięć jest zapisywana.
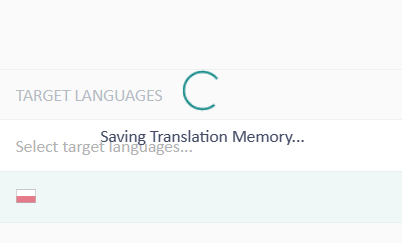
Utworzona pamięć tłumaczeń będzie widoczna w Resources - Translation Memories.
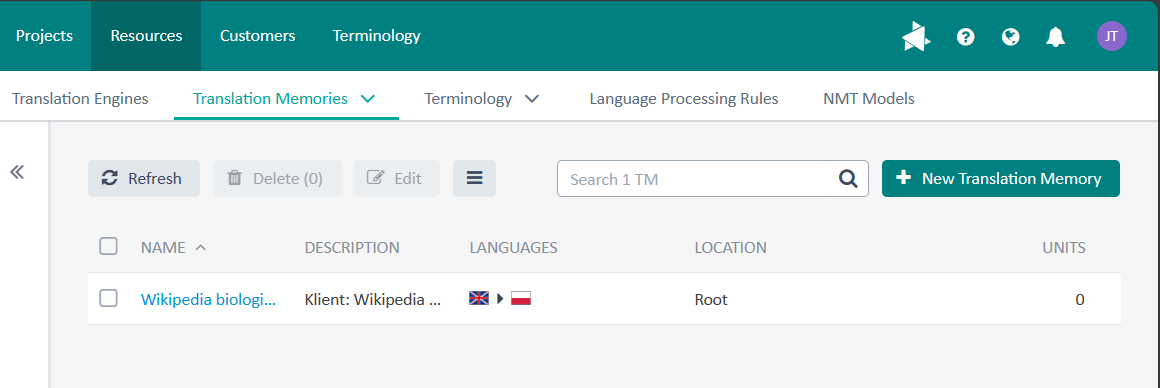
Żeby móc skorzystać z pamięci tłumaczeń w projekcie, potrzebujemy Translation Engine.







Tworzenie Translation Engine (TE)
Przechodzimy do Resources - Translation Engines.
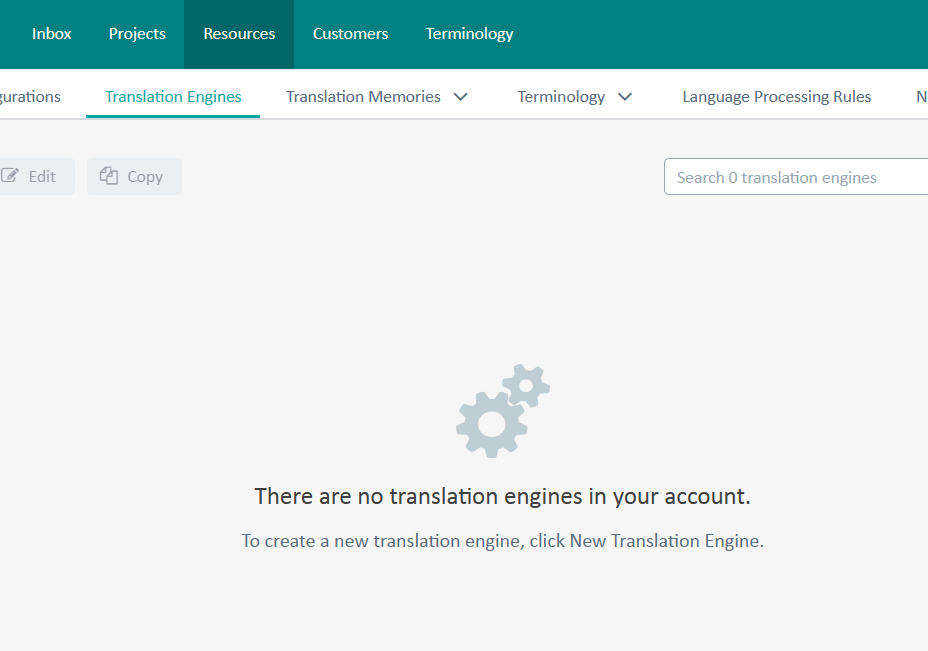 Na początku nie zobaczymy żadnych Translation Engines.
Na początku nie zobaczymy żadnych Translation Engines.Teraz klikamy + New Translation Engine.
Teraz mamy kilka pól do wypełnienia. Górna część ekranu wygląda podobnie, jak przy tworzeniu pamięci tłumaczeń.
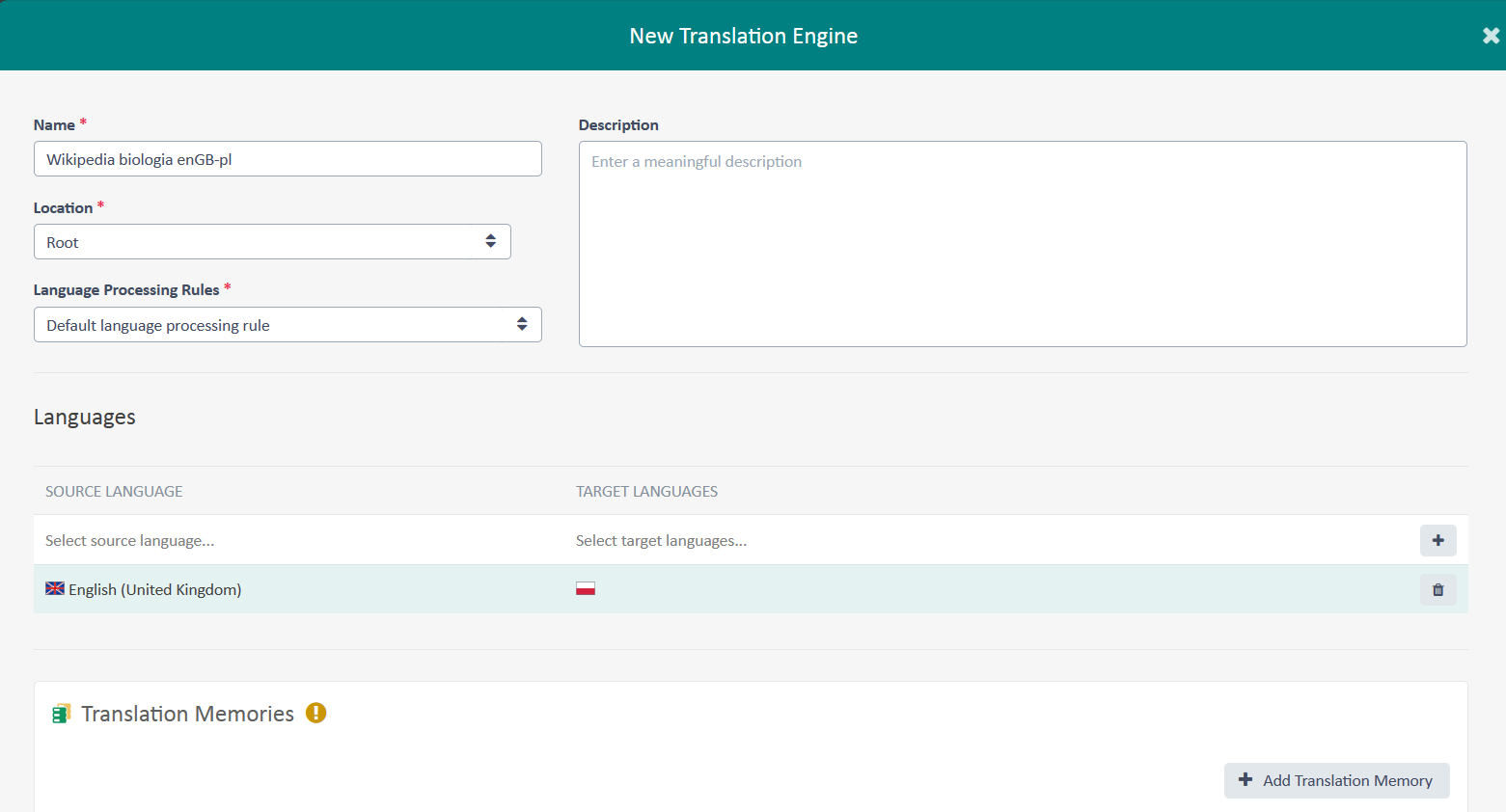
Name – nazwa Translation Engine. Tutaj zastosowałem podejście identyczne jak przy nazewnictwie dla pamięci tłumaczeń.
Description – dodatkowe informacje, które chcielibyśmy przechowywać razem z Trannslation Engine.
Location – miejsce zapisu Translation Engine w naszej chmurze. Jeżeli dodatkowo utworzyliśmy sobie klientów (Customers), to możemy TE przypisać do konkretnego klienta. Służy to organizacji i uporządkowaniu pracy. Ja nie utworzyłem żadnych klientów i wybrałem poziom Root jako miejsce na trzymanie swoich zasobów językowych.
Language Processing Rules – ta pozycja powinna sama się wypełnić, kiedy wybierzemy Location. Jeżeli się nie wypełniła, należy kliknąć strzałki znajdujące się po prawej stronie i wybrać pozycję z listy.
Source Language / Target Language – określamy język źródłowy oraz docelowy. Translation Engine muszą mieć identyczne podgrupy językowe jak nasze pamięci tłumaczeń!
Teraz jeszcze trzeba dodać przynajmniej pamięć tłumaczeń. W tym celu klikamy +Add Translation Memory.
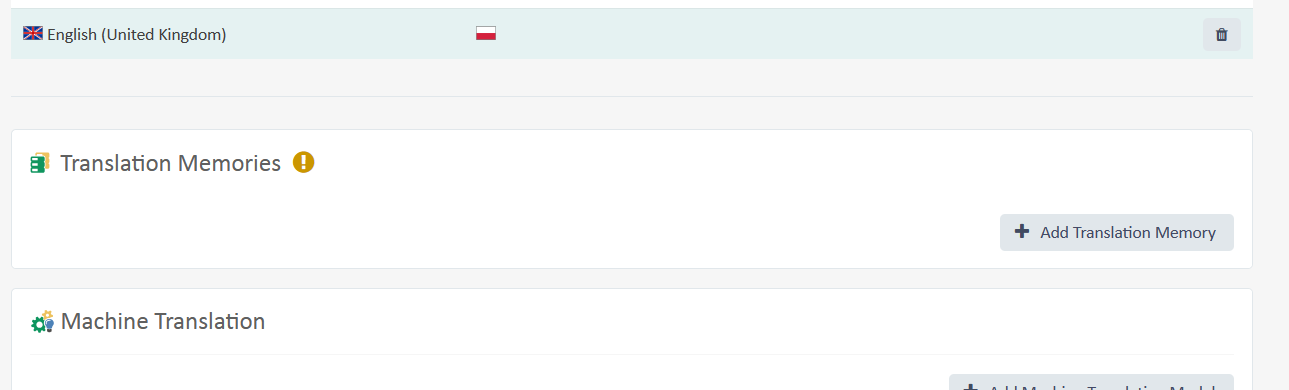
Wyświetli się okno z naszymi chmurowymi pamięciami tłumaczeń.
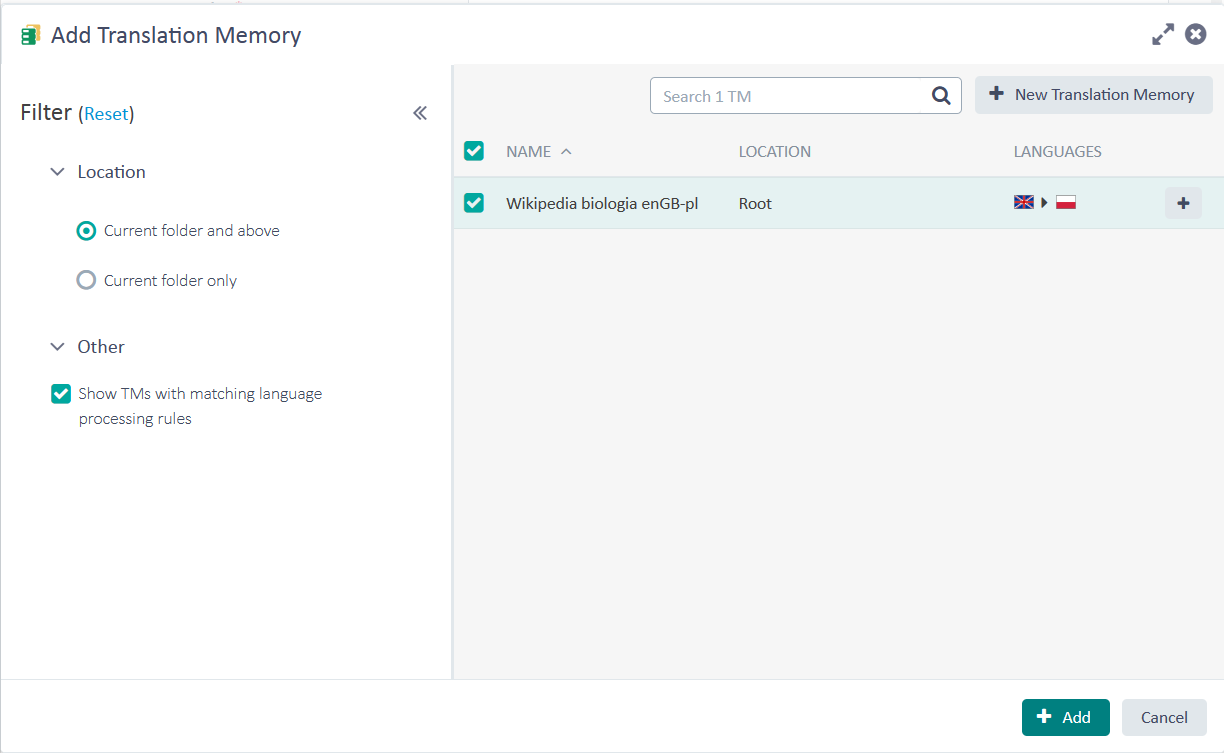 Zaznaczone pamięci zostaną dodane do Translation Engine.
Zaznaczone pamięci zostaną dodane do Translation Engine.Zaznaczamy tę pamięć (lub pamięci, jeżeli chcemy mieć kilka w Translation Engine) i klikamy przycisk + Add.
W ten sposób wrócimy do poprzedniego okna i zobaczymy dodane przez nas pamięci tłumaczeń.
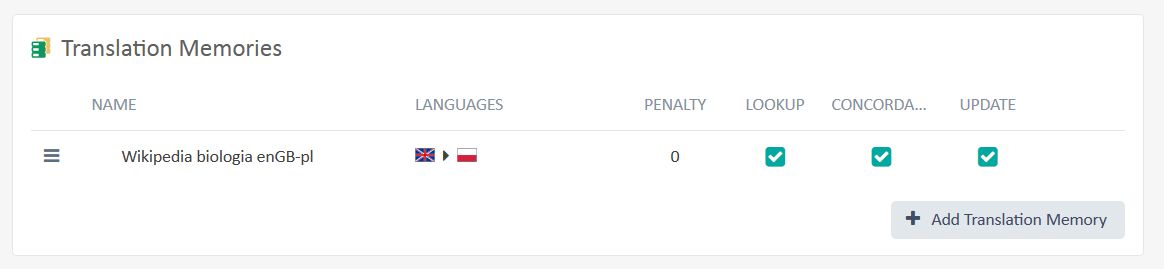
Upewniamy się, że wszystkie pola wyboru są zaznaczone (w szczególności przy Update) i możemy kliknąć Create, żeby utworzyć Translation Engine. Dodawaniem słowników terminologicznych oraz tłumaczenia maszynowego zajmiemy się innym razem.
Jeżeli chcemy pracować z kilkoma pamięciami, ale nie wszystkie mają się aktualizować, to można dla wybranych TM odznaczyć Update. Ale korzystajmy z tego rozważanie!
Utworzony Translation Engine pojawi się na liście.
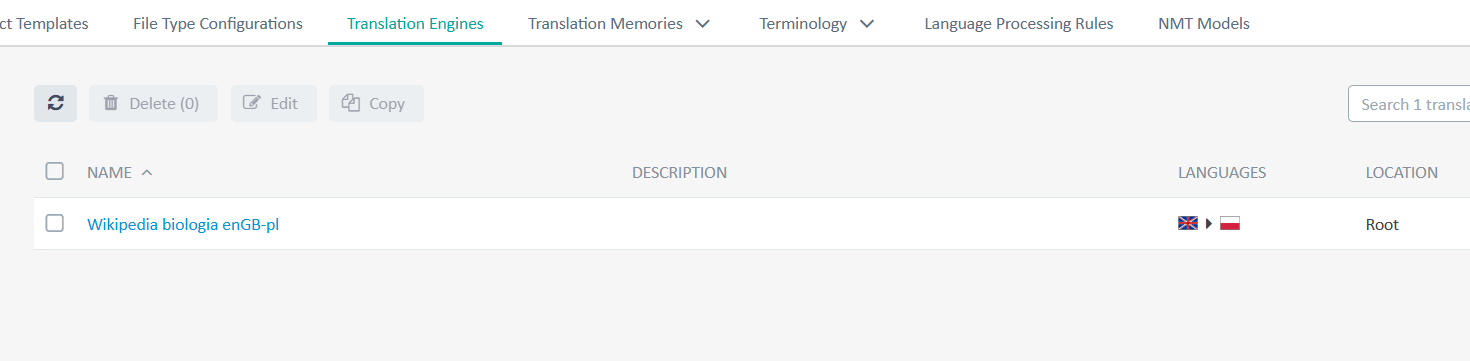
Gdybyśmy chcieli zmienić dodane do jakiegoś Translation Engine zasoby, wystarczy kliknąć jego nazwę i znajdziemy się w punkcie 3. tej części samouczka.
Ten sam Translation Engine może zawierać pamięci z różnych par językowych w różnych kierunkach – wystarczy jej dodać. Wówczas możemy dodać pasujące pamięci tłumaczeń.
Można też przyjąć odrębne podejście i utworzyć tyle Translation Engine, ile par językowych obsługujemy. A nawet dzielić je dalej na klientów. Wszystko zależy od nas.





Przygotowanie szablonu projektów
Ostatnim krokiem przygotowania naszego chmurowego Tradosa będzie edycja szablonu projektów. Szablony projektów pomagają szybką zacząć pracę, ponieważ mają już wybraną parę językową oraz Translation Engine (czyli pamięci tłumaczeń i ewentualnie terminologię i tłumaczenie maszynowe).
Możemy mieć przygotowanych kilka szablonów projektów, w różnych parach językowych i kierunkach, dla różnych klientów. Wówczas np. otrzymując zlecenie od Samsunga, wybieramy szablon utworzony pod tego klienta i w zasadzie wystarczy wybrać dokumenty, które będziemy tłumaczyli. Szablon projektu ustawi parę językową, pamięci tłumaczeń i ewentualnie terminologię czy tłumaczenie maszynowe.
Podobnie jak przy tworzeniu pamięci tłumaczeń czy Translation Engine, trzeba wypełnić kilka pól.
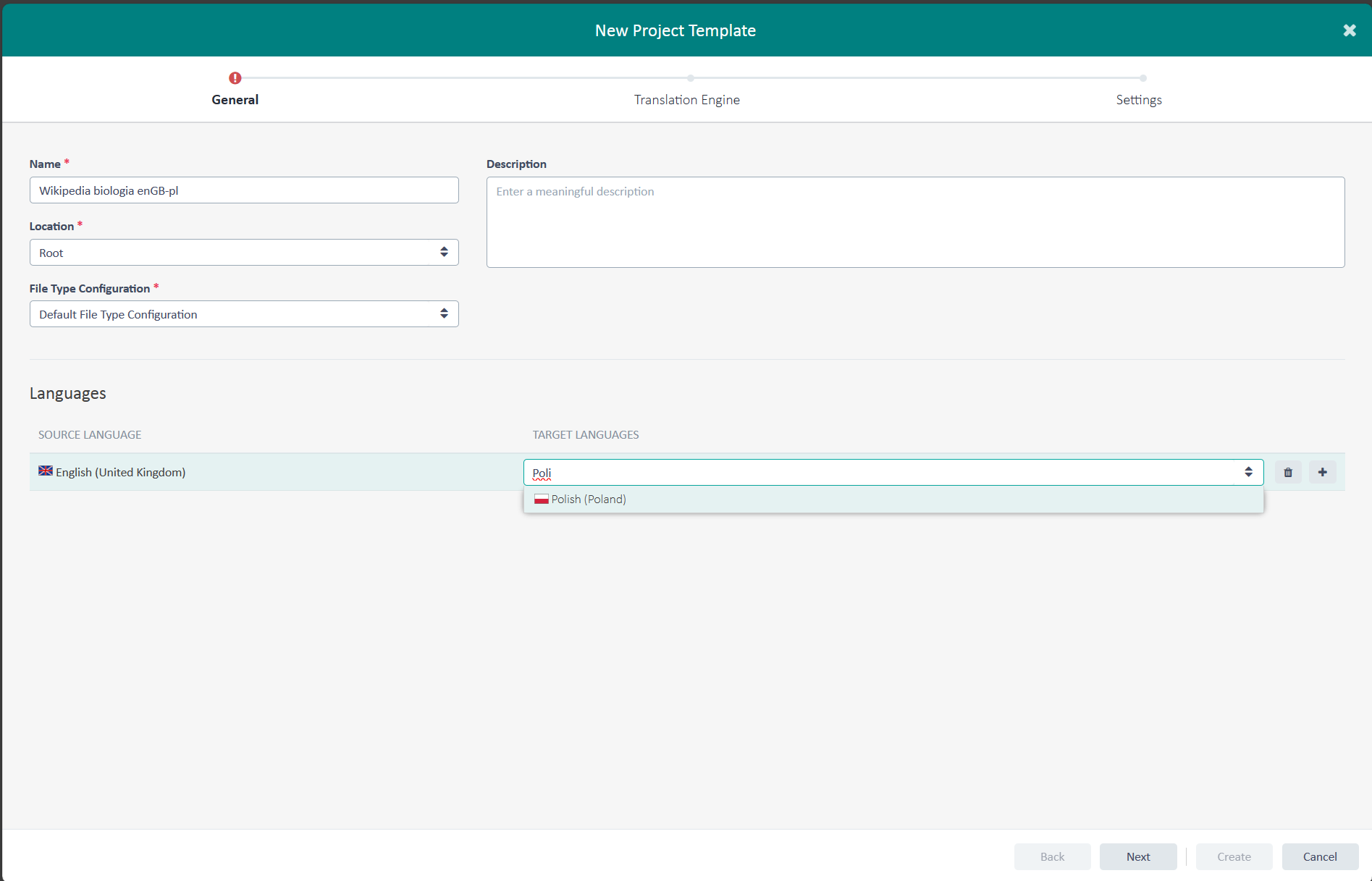
Name – nazwa dla szablonu. Tutaj zastosowałem podejście identyczne jak przy nazewnictwie dla pamięci tłumaczeń oraz Translation Engine.
Description – dodatkowe informacje, które chcielibyśmy przechowywać razem z szablonem.
Location – miejsce zapisu szablonu projektu w naszej chmurze. Jeżeli dodatkowo utworzyliśmy sobie klientów (Customers), to możemy szablon przypisać do konkretnego klienta. Służy to organizacji i uporządkowaniu pracy. Ja nie utworzyłem żadnych klientów i wybrałem poziom Root jako miejsce na trzymanie swoich zasobów językowych.
File Type Configuration – ta pozycja powinna sama się wypełnić, kiedy wybierzemy Location. Jeżeli się nie wypełniła, należy kliknąć strzałki znajdujące się po prawej stronie i wybrać pozycję z listy.
Source Language / Target Language – określamy język źródłowy oraz docelowy. W kolejnym kroku do szablonu będzie można dodać te Translation Engines, które będą pasowały do języków, które właśnie określiliśmy.
Klikamy Next i teraz czas wybrać Translation Engine.
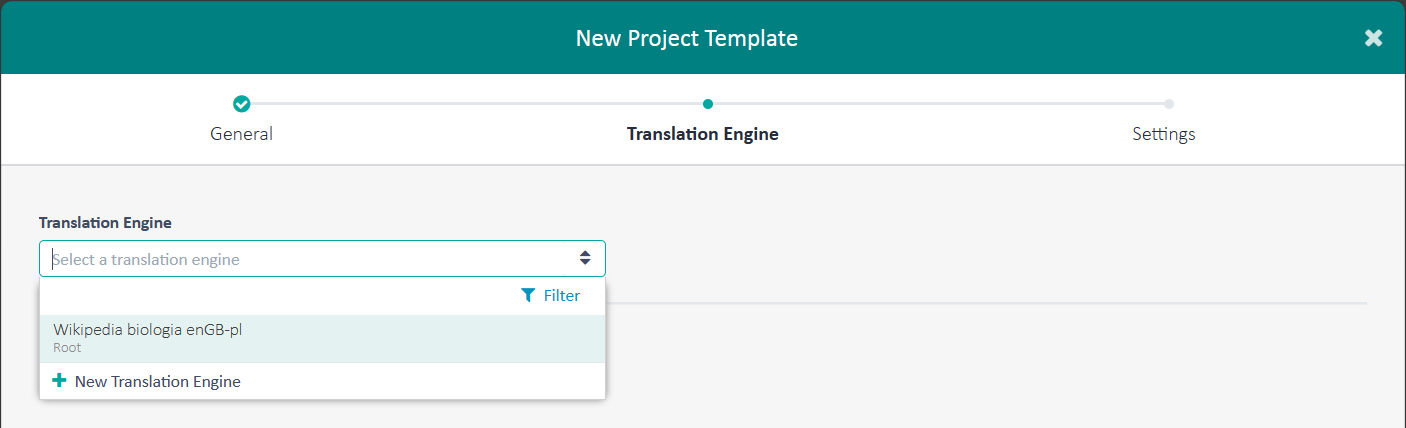 Żeby wybrać Translation Engine, trzeba kliknąś dwa trójkąty znajdujące się w ramce po prawej stronie.
Żeby wybrać Translation Engine, trzeba kliknąś dwa trójkąty znajdujące się w ramce po prawej stronie.Po wybraniu Translation Engine zostaną załadowane ustawienia. Jeżeli potrzebujemy coś zmienić, możemy to tutaj zrobić.
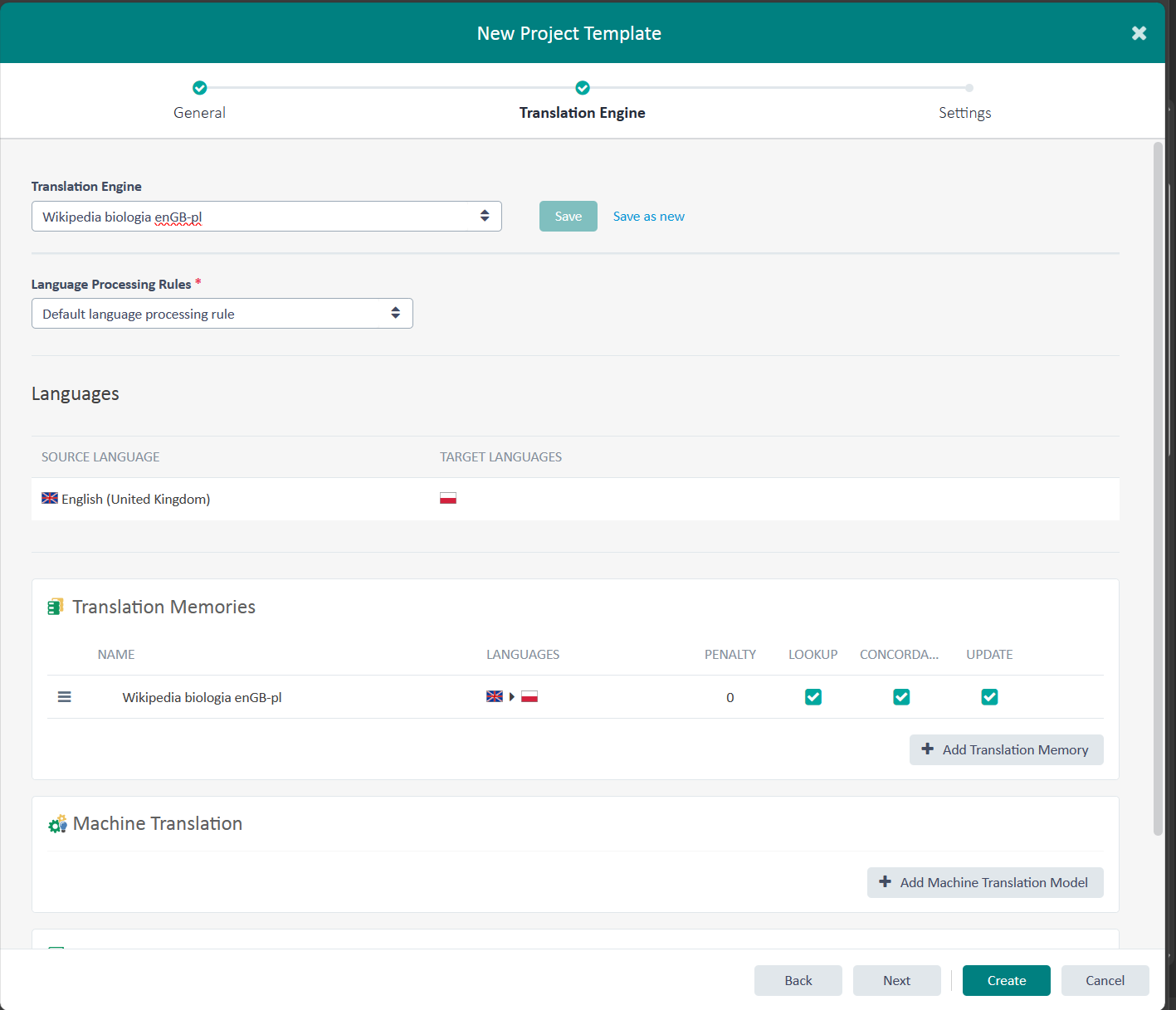
Jeżeli nie, klikamy Next.
Pozycja Settings jest ostatnim krokiem konfiguracji szablonu projektu.
Początkujący użytkownicy mogą zostawić wszystko, jak jest. Na tym etapie nie ma potrzeby modyfikować tych ustawień. Klikamy Create i platforma jest już skonfigurowana do pracy!



W kolejnym artykule omawiam dodawanie tłumaczenia maszynowego do Translation Engine.
→ Powrót do wszystkich artykułów w Trados – kompendium wiedzy.
Masz pytania lub sugestie do tego tekstu? Napisz do mnie!